
Built for researchers in academia and industry whose needs aren't met by hyperscalers, local clusters, or neo-clouds.
"We switched due to their competitive pricing and reliability" - Anshu Avinash, Tech Dir, AI and Search

"Love Cloudexe for their pricing and stellar support!" - Soumyadeep Bakshi, Co-founder

"Deployments become effortless with intuitive interface." - Prof. Fernando De La Torre
"Ideal UX for managing multi-campus education/research infrastructure" - Prof. Snehanshu Saha

"Runtime abstraction is clean...provided excellent support throughout..." - Dr. Rolando Garcia, Presidential Fellow
"We switched due to their competitive pricing and reliability" - Anshu Avinash, Tech Dir, AI and Search
"Love Cloudexe for their pricing and stellar support!" - Soumyadeep Bakshi, Co-founder
"Deployments become effortless with intuitive interface." - Prof. Fernando De La Torre
"Ideal UX for managing multi-campuseducation/research infrastructure" - Prof. Snehanshu Saha
"Runtime abstraction is clean...provided excellent support throughout..." - Dr. Rolando Garcia, Presidential Fellow
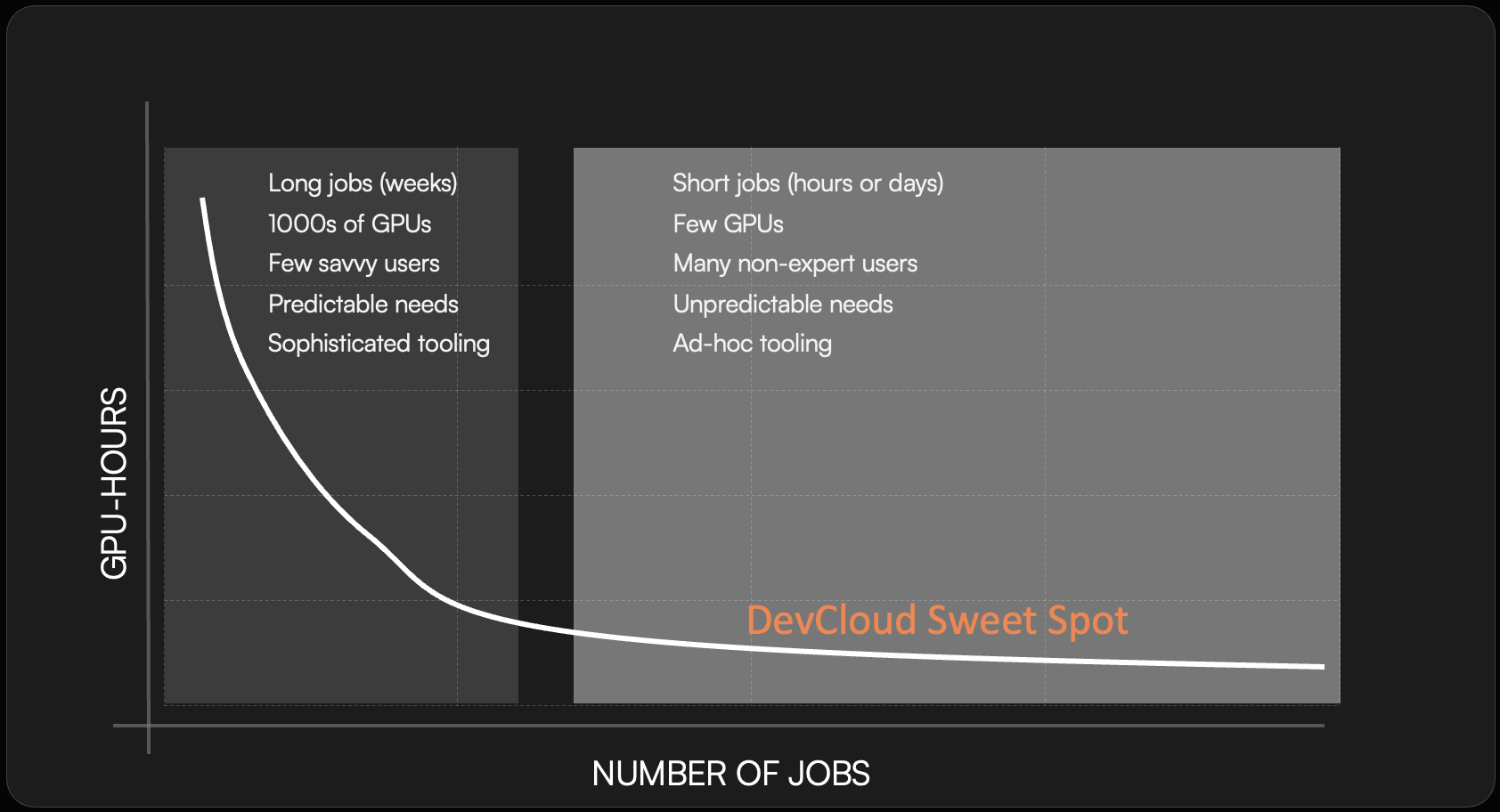
Research teams face unique challenges that traditional cloud platforms just can't address. The demands of small, fast-moving teams require a tailored solution.
DevCloud is the first end-to-end cloud platform specifically designed for the research community, offering an optimized experience for both academia and industry.
If you are managing a team of researchers or developers who use GPUs in many different ways (training models, running simulations, classic ML workloads, etc.), this product is for you.
DevCloud's unique architecture is based on patented Hardware/Software Disaggregation, which unbundles the "server" concept into separate components:
This disaggregation enables the dynamic pairing of software environments with hardware over ultra-low-latency networks, improving flexibility, resource utilization, and cost efficiency.
| Architectural Change | User Implication |
|---|---|
| No explicit server acquisition/release (GPUs only used during workload execution) | Improved GPU fleet utilization and reduced customer costs. |
| No setup required for GPU servers (access to multiple neocloud partners) | Better GPU availability and further cost reduction. |
| No need to capture dependencies or sync uploads/downloads | Faster iterations and debugging, leading to improved user experience. |
We are a team of experienced engineers and entrepreneurs with deep expertise in building GPU cloud infrastructure at leading companies like Intel, NVIDIA, Google, and others. We shipped the first CUDA GPU at NVIDIA, the first Xe GPU at Intel, and built the core tech for Google's Stadia Cloud Gaming service. Based in Silicon Valley, we are passionate about solving the unique challenges faced by researchers in academia and industry.
For corporate inquiries, reach us at info@cloudexe.tech.
